 A little while back, I travelled to Canberra with my partner, Sophie Couchman, to help Tim Sherratt and Kate Bagnall with their ‘Real Face of White Australia’ project. We spent the weekend transcribing documents relating to the history of White Australia, and Australia’s historical attempts to exclude people who were not ‘white’.
A little while back, I travelled to Canberra with my partner, Sophie Couchman, to help Tim Sherratt and Kate Bagnall with their ‘Real Face of White Australia’ project. We spent the weekend transcribing documents relating to the history of White Australia, and Australia’s historical attempts to exclude people who were not ‘white’.
First, a bit of history. There was a period (not so long ago, in the scheme of things) when Australia used a bureaucratic system to bar entry to anyone who wasn’t white. As part of that process, we used a ‘dictation test’ to bar entry to anyone deemed undesirable.
If you were already a resident in Australia (because, for example, you had been born here) and didn’t look white, you needed to get an exemption from the dictation test before you went overseas. If you didn’t, you might not be allowed to re-enter the country. These ‘Certificates Exempting from Dictation Test’ are all stored in Australian archives, and provide valuable insights into that period of history.
Unfortunately, they are currently all locked away. Not because of the issues that normally relate to Open Access: ‘Open’ versus ‘Closed’ legal permissions (although there are issues there) or ‘ ‘Free speech’ versus ‘Free beer’ (versus ‘Free puppies’) monetary issues. No. This information is locked away because it is handwritten on paper. Even where the archive has digitised the certificates, there is no reliable way to optically recognize (OCR) the characters.
We lose sight, sometimes, of how much stuff is still locked away on paper, in handwriting. That’s where I came in. With my partner, Sophie, I went to Canberra and spent a couple of days transcribing this handwritten data.
Through this project, 2,662 pages have been classified. That represents 20% of the 13,000 digitised pages in the National Archive of Australia Series ST84/1 that have been digitised so far. But only a small percentage of that series has been digitised, and that is just one series in the New South Wales archives. There are more in the other States. This is just one set of forms, from one bureaucratic process.
Before a certain point, everything in the archive is handwritten. Everything! So much work to be done. So much potential data.
So, what did the work look like? It looked like this…
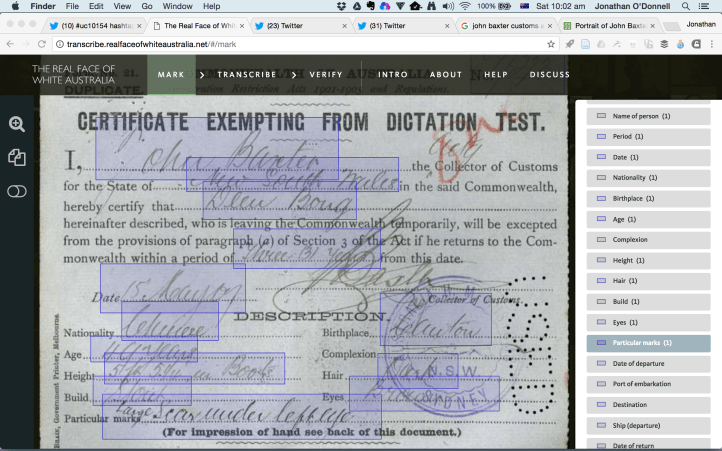
Here, I am going through the process of marking up the handwritten information on Deen Bong’s certificate. On this certificate, John Baxter, the acting Collector of Customs for New South Wales has given Deen Bong a certificate for three years, starting 15 May 1907. The certificate records that Deen was Chinese, from Canton, aged 49 years. He stood 5 foot, 5 inches in boots. He had dark hair, brown eyes, a solid build and a large scar under his left eye.
That is, he was about four years younger and about 15 cm shorter than me, 110 years ago. And he had a scar.
As well as a physical description, each certificate also had photographs attached. Here are some that I came across:



On the back of each certificate was a hand print. While the photos were interesting, I found the hand prints to be enormously evocative.

Once the information has been marked, it can then be transcribed and verified. The whole thing works incredibly simply.
I love this project because it opens up data that cannot be accessed any other way, and that data is available to anyone via Github.
With this data, historians can know more about these people, and this period of history. Raw data like this is extraordinarily valuable, as it helps to illuminate other documents written at the time: government reports, newspaper articles, letters, books…
It can shed light on how government bureaucracies actually worked, as opposed to how they were described in the regulations.
It provides a spotlight on particular people because any given document can say that this person was in this place at this time. It gives a sense of how mobile people were at this time, travelling between Australia and China relatively frequently.
Because it is open, it can be helpful and interesting in unexpected ways, and unexpected areas, like fashion and handwriting.
It is especially helpful for people trying to explore their own family tree. Imagine suddenly coming across a photo of your great grandmother, out of the government archive. There are stories in there…
It opens up learning opportunities. Tim teaches a unit called Exploring Digital Heritage at the University of Canberra. The Real Face of White Australia project gave his students something real to grapple with. They responded magnificently.
Kate and Sophie are using it to their research to help people to understand where their ancestors came from. Their Hometown Heritage Tours take decedents back to the ancestral villages in China.
Of course, this sort of effort doesn’t come out of thin air. Tim and Kate have been talking about this project for seven years. Mostly, they were waiting for the software to emerge.
The project is built on Scribe, software for crowdsourcing document transcription. Scribe is designed to extract highly structured, normalisable data from a set of digitised materials, just like the Certificates of Exemption from Dictation Test. It is, of course, open source software.
Scribe has been produced and maintained by a collaboration between the New York Public Library Labs and Zooniverse. If you haven’t had a look at Zooniverse, go and take a look. Zooniverse is an open platform for crowdsourced data processing. It is amazing, and utterly addictive. They have a huge range of projects, including working on personnel files of ANZAC soldiers; fragmentary manuscripts in Hebrew or Arabic scripts; extracting historic weather measurements from whaling log books; and a personal favourite, identifying animals of the Serengeti.
These projects break the processing of data into tiny parts, so that anybody can do it. They all work on the web, so that people can do them anywhere. And they are open, so that other researchers can build on what has come before.
If you want to learn more of the skills that sit behind these projects, there is also a movement to help people learn from one another. Research Bazaar is a worldwide festival promoting the digital literacy emerging at the center of modern research. It provides a space where researchers can learn these skills from one another, in a supportive and open environment.
Finally, it opens up the future.
Because all of this software is freely available, because Tim has shown us how it can be done, and because there is a mountain of information to be transcribed around the country, Sophie Couchman is now setting up a similar project in Victoria with the support of members of the Chinese Australian Family Historians of Victoria. Similar projects could allow you to pull almost any series out of the archive and encode it.
This article began life as a presentation for Open Access week at La Trobe University, 23 October 2017. Thanks to La Trobe for inviting me to speak.

What a wonderful project!!!
From experience as a now ‘non-practising’ archivist in the collective archives context, there is just so much out there that needs to be done…in all sorts of collections…
The SLV is doing a good job doing just this with the newspapers in its collections..a wonderfully rich source of history sitting undiscovered…they often have a call out for volunteers to ‘proof’ digitised copies.
Begs the question…in this fast moving digital environment, despite best efforts of the PRO, AA etc. etc., what will there be to see in 100 yrs time?
LikeLike
Thanks, Amanda
This is the big question, and there are a few parts to it. One is technical – how do we cope with out-of-date formats?
The other is more practical – what is the business model for maintaining these archives. Organisations like the State Library of Victoria and government archives have a very clear business model – the government funds them to preserve stuff. It isn’t quite so clear for other organisations and collections.
Then there are issues related to being able to find what you want. With federated collections of information, finding stuff can become really tricky. There is currently no universal standards for metadata for research collections, for example. Biology have their controlled lists, and social science have their standards, but there are currently few useful crosswalks or other methods of federating metadata.
It is tricky.
Jonathan
LikeLike